PgSQL · 特性分析 · PG主备流复制机制
本文来自于阿里云RDS-数据库内核组,文章地址。笔者读完此文,感觉作者对 PostgreSQL 流复制 streaming replication 的机制解析的非常透彻,是一遍非常好的技术分享文档。文章采用知识共享署名-非商业性使用-相同方式共享 3.0 未本地化版本许可协议,因此笔者将本文收录于自己的博客中,方便日后学习检索。
PostgreSQL在9.0之后引入了主备流复制机制,通过流复制,备库不断的从主库同步相应的数据,并在备库apply每个WAL record,这里的流复制每次传输单位是WAL日志的record。而PostgreSQL9.0之前提供的方法是主库写完一个WAL日志文件后,才把WAL日志文件传送到备库,这样的方式导致主备延迟特别大。同时PostgreSQL9.0之后提供了Hot Standby,备库在应用WAL record的同时也能够提供只读服务,大大提升了用户体验。
主备总体结构
PG主备流复制的核心部分由walsender,walreceiver和startup三个进程组成。 walsender进程是用来发送WAL日志记录的,执行顺序如下:
1 | PostgresMain()->exec_replication_command()->StartReplication()->WalSndLoop()->XLogSendPhysical() |
walreceiver进程是用来接收WAL日志记录的,执行顺序如下:
1 | sigusr1_handler()->StartWalReceiver()->AuxiliaryProcessMain()->WalReceiverMain()->walrcv_receive() |
startup进程是用来apply日志的,执行顺序如下:
1 | PostmasterMain()->StartupDataBase()->AuxiliaryProcessMain()->StartupProcessMain()->StartupXLOG() |
下图是PG主备总体框架图:
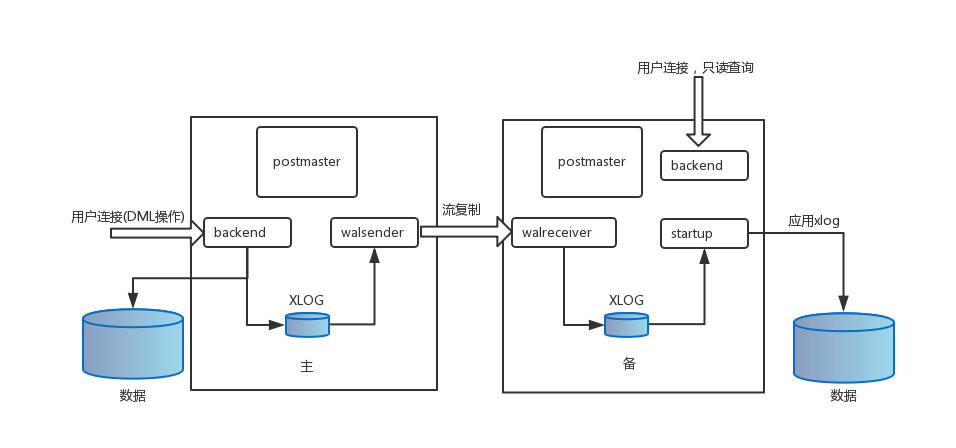
walsender和walreceiver进程流复制过程
walsender和walreceiver交互主要分为以下几个步骤:
- walreceiver启动后通过recovery.conf文件中的primary_conninfo参数信息连向主库,主库通过连接参数replication=true启动walsender进程;
- walreceiver执行identify_system命令,获取主库systemid/timeline/xlogpos等信息,执行TIMELINE_HISTORY命令拉取history文件;
- 执行wal_startstreaming开始启动流复制,通过walrcv_receive获取WAL日志,期间也会回应主库发过来的心跳信息(接收位点、flush位点、apply位点),向主库发送feedback信息(最老的事务id),避免vacuum删掉备库正在使用的记录;
- 执行walrcv_endstreaming结束流复制,等待startup进程更新receiveStart和receiveStartTLI,一旦更新,进入步骤2。
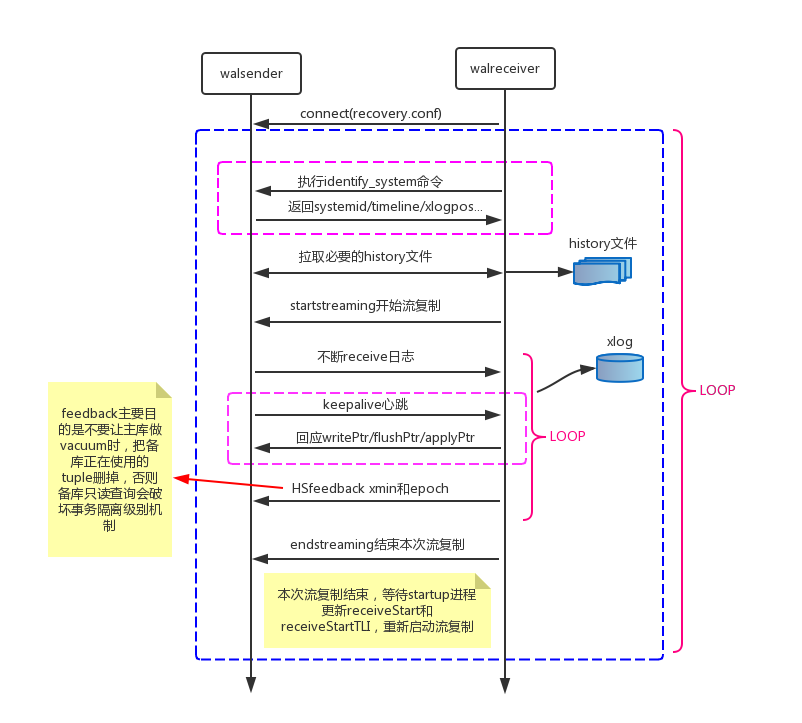
walreceiver和startup进程
startup进程进入standby模式和apply日志主要过程:
-
读取pg_control文件,找到redo位点;读取recovery.conf,如果配置standby_mode=on则进入standby模式。
-
如果是Hot Standby需要初始化clog、subtrans、事务环境等。初始化redo资源管理器,比如Heap、Heap2、Database、XLOG等。
-
读取WAL record,如果record不存在需要调用XLogPageRead->WaitForWALToBecomeAvailable->RequestXLogStreaming唤醒walreceiver从walsender获取WAL record。
-
对读取的WAL record进行redo,通过record->xl_rmid信息,调用相应的redo资源管理器进行redo操作。比如heap_redo的XLOG_HEAP_INSERT操作,就是通过record的信息在buffer page中增加一个record:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25MemSet((char *) htup, 0, sizeof(HeapTupleHeaderData));
/* PG73FORMAT: get bitmap [+ padding] [+ oid] + data */
memcpy((char *) htup + offsetof(HeapTupleHeaderData, t_bits),
(char *) xlrec + SizeOfHeapInsert + SizeOfHeapHeader,
newlen);
newlen += offsetof(HeapTupleHeaderData, t_bits);
htup->t_infomask2 = xlhdr.t_infomask2;
htup->t_infomask = xlhdr.t_infomask;
htup->t_hoff = xlhdr.t_hoff;
HeapTupleHeaderSetXmin(htup, record->xl_xid);
HeapTupleHeaderSetCmin(htup, FirstCommandId);
htup->t_ctid = xlrec->target.tid;
offnum = PageAddItem(page, (Item) htup, newlen, offnum, true, true);
if (offnum == InvalidOffsetNumber)
elog(PANIC, "heap_insert_redo: failed to add tuple");
freespace = PageGetHeapFreeSpace(page); /* needed to update FSM below */
PageSetLSN(page, lsn);
if (xlrec->flags & XLOG_HEAP_ALL_VISIBLE_CLEARED)
PageClearAllVisible(page);
MarkBufferDirty(buffer);还有部分redo操作(vacuum产生的record)需要检查在Hot Standby模式下的查询冲突,比如某些tuples需要remove,而存在正在执行的query可能读到这些tuples,这样就会破坏事务隔离级别。通过函数ResolveRecoveryConflictWithSnapshot检测冲突,如果发生冲突,那么就把这个query所在的进程kill掉。
-
检查一致性,如果一致了,Hot Standby模式可以接受用户只读查询;更新共享内存中XLogCtlData的apply位点和时间线;如果恢复到时间点,时间线或者事务id需要检查是否恢复到当前目标;
-
回到步骤3,读取next WAL record。
