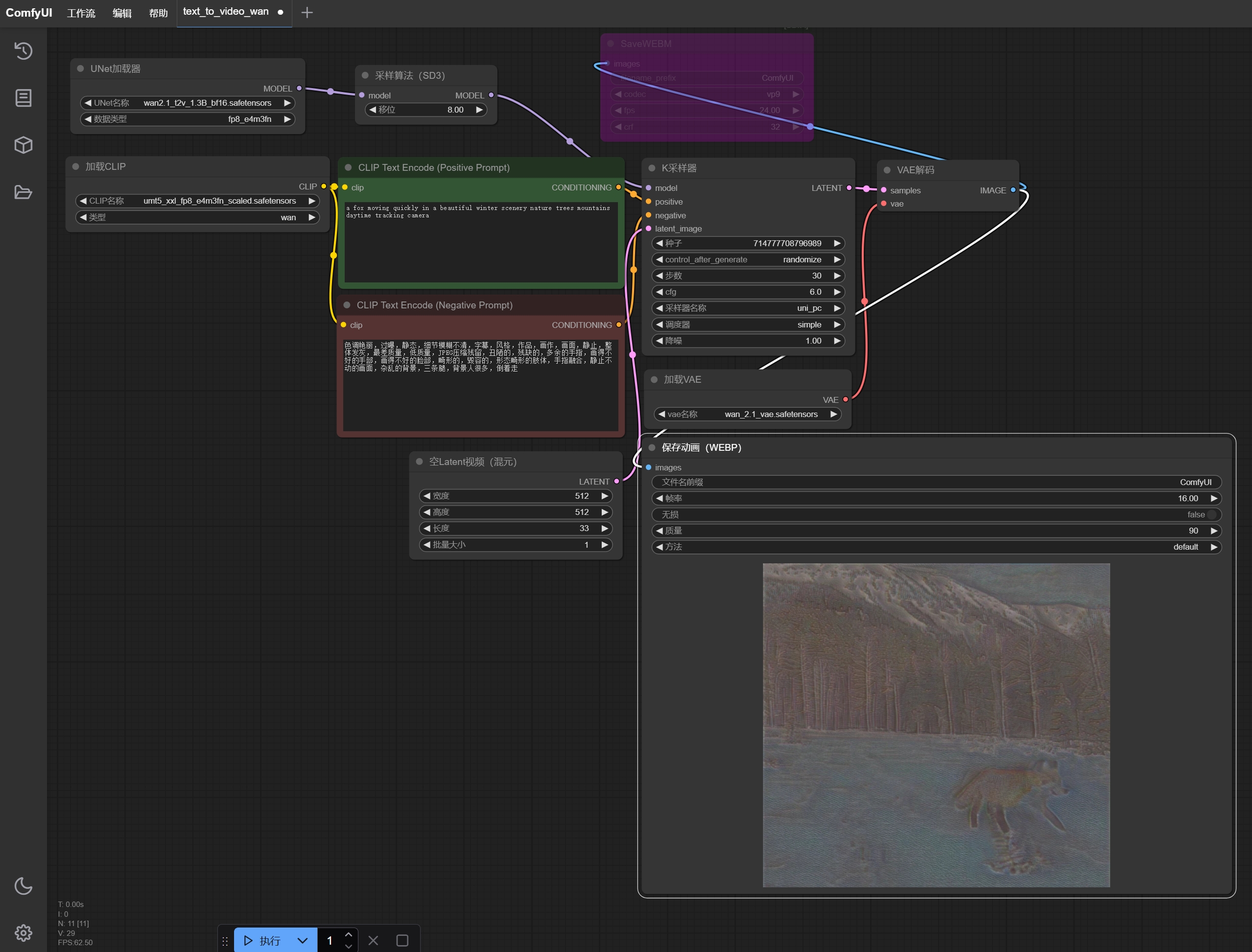
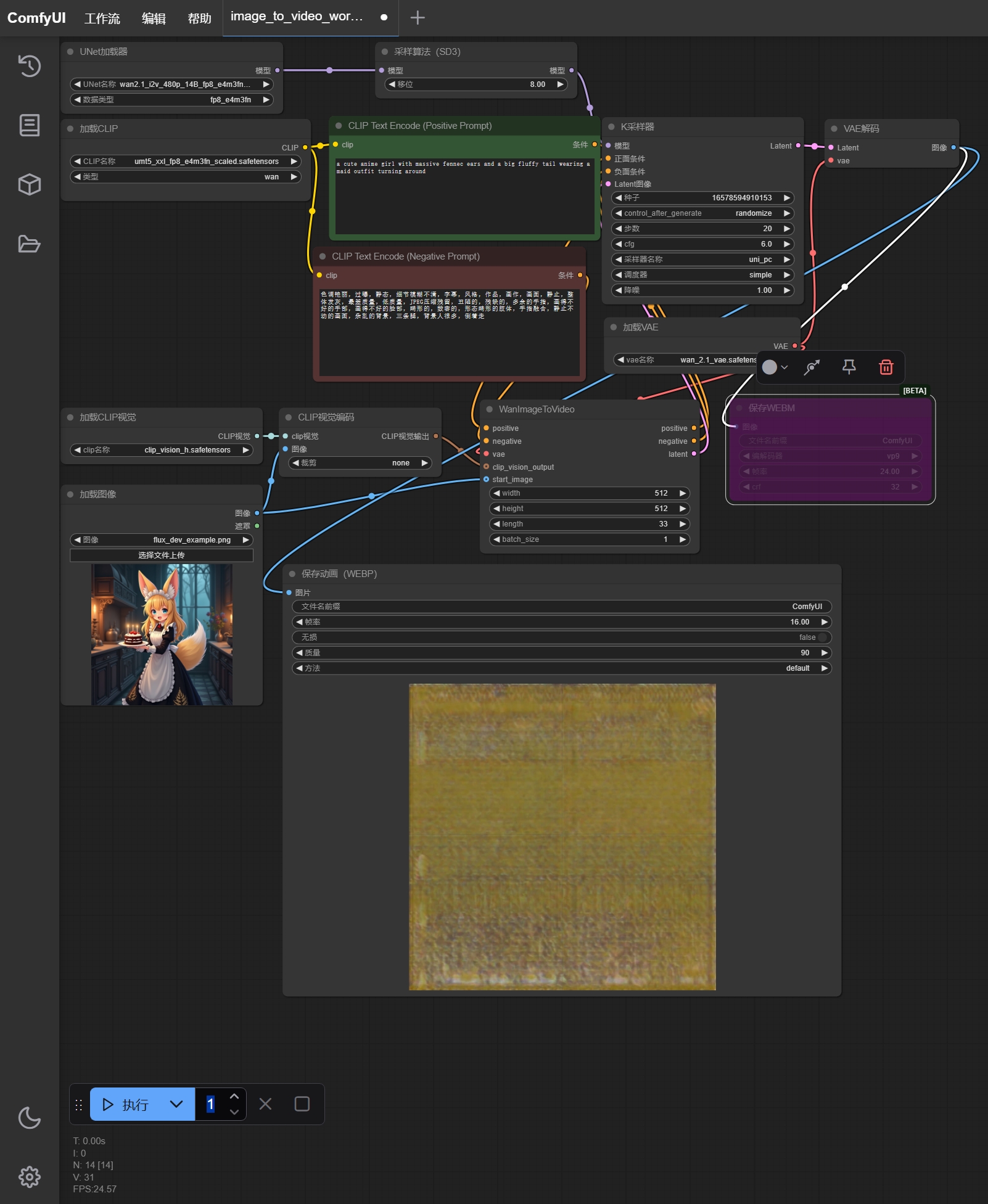
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
| ComfyUI-Zluda master ≡ ?1 3.10.16 59.198s⠀ .\comfyui.bat --use-split-cross-attention
*** Checking and updating to new version if possible
Already up to date.
[START] Security scan
[DONE] Security scan
** ComfyUI startup time: 2025-03-03 22:35:41.078
** Platform: Windows
** Python version: 3.10.16 | packaged by Anaconda, Inc. | (main, Dec 11 2024, 16:19:12) [MSC v.1929 64 bit (AMD64)]
** Python executable: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\venv\Scripts\python.exe
** ComfyUI Path: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda
** ComfyUI Base Folder Path: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda
** User directory: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\user
** ComfyUI-Manager config path: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\user\default\ComfyUI-Manager\config.ini
** Log path: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\user\comfyui.log
Prestartup times for custom nodes:
10.5 seconds: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\custom_nodes\ComfyUI-Manager
Warning, you are using an old pytorch version and some ckpt/pt files might be loaded unsafely. Upgrading to 2.4 or above is recommended.
***----------------------ZLUDA-----------------------------***
:: ZLUDA detected, disabling non-supported functions.
:: CuDNN, flash_sdp, mem_efficient_sdp disabled).
***--------------------------------------------------------***
:: Device : Radeon RX 580 Series [ZLUDA]
Total VRAM 8192 MB, total RAM 98210 MB
pytorch version: 2.2.1+cu118
Set vram state to: NORMAL_VRAM
Device: cuda:0 Radeon RX 580 Series [ZLUDA] : native
Using sub quadratic optimization for attention, if you have memory or speed issues try using: --use-split-cross-attention
ComfyUI version: 0.3.18
[Prompt Server] web root: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\venv\lib\site-packages\comfyui_frontend_package\static
[ComfyUI-Manager] network_mode: public
Import times for custom nodes:
0.0 seconds: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\custom_nodes\ComfyUI-deepcache
0.0 seconds: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\custom_nodes\websocket_image_save.py
2.6 seconds: C:\Users\lewlh\workspaceWin\ComfyUI-Zluda\custom_nodes\ComfyUI-Manager
Starting server
To see the GUI go to: http://127.0.0.1:8188
[ComfyUI-Manager] default cache updated: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/model-list.json
[ComfyUI-Manager] default cache updated: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/alter-list.json
[ComfyUI-Manager] default cache updated: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/github-stats.json
[ComfyUI-Manager] default cache updated: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/extension-node-map.json
[ComfyUI-Manager] default cache updated: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/custom-node-list.json
FETCH ComfyRegistry Data: 5/36
FETCH ComfyRegistry Data: 10/36
FETCH ComfyRegistry Data: 15/36
FETCH ComfyRegistry Data: 20/36
FETCH ComfyRegistry Data: 25/36
FETCH ComfyRegistry Data: 30/36
FETCH ComfyRegistry Data: 35/36
FETCH ComfyRegistry Data [DONE]
[ComfyUI-Manager] default cache updated: https://api.comfy.org/nodes
nightly_channel: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/remote
FETCH DATA from: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/custom-node-list.json [DONE]
[ComfyUI-Manager] All startup tasks have been completed.
got prompt
Using split attention in VAE
Using split attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.bfloat16
Requested to load CLIPVisionModelProjection
loaded completely 6323.2 1208.09814453125 True
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cpu, dtype: torch.float16
Requested to load WanTEModel
loaded partially 5629.075 5619.477012634277 0
0 models unloaded.
loaded partially 5619.477012729645 5619.477012634277 0
Requested to load WanVAE
loaded partially 64.0 63.99991416931152 0
model weight dtype torch.float8_e4m3fn, manual cast: torch.bfloat16
model_type FLOW
Requested to load WAN21
0 models unloaded.
loaded partially 64.0 63.60723876953125 0
75%|███████████████████████████████████████████████████████████████ | 15/20 [5:37:34<1:53:39, 1363.94s/
80%|███████████████████████████████████████████████████████████████████▏ | 16/20 [6:00:31<1:31:12, 1368.07s/
85%|███████████████████████████████████████████████████████████████████████▍ | 17/20 [6:23:14<1:08:19, 1366.55s/
90%|█████████████████████████████████████████████████████████████████████████████▍ | 18/20 [6:45:55<45:29, 1364.77s/
95%|█████████████████████████████████████████████████████████████████████████████████▋ | 19/20 [7:08:36<22:43, 1363.78s/
100%|██████████████████████████████████████████████████████████████████████████████████████| 20/20 [7:31:18<00:00, 1363.08s/
100%|██████████████████████████████████████████████████████████████████████████████████████| 20/20 [7:31:18<00:00, 1353.91s/it]
Requested to load WanVAE
0 models unloaded.
loaded partially 64.0 63.99991416931152 0
Prompt executed in 28429.51 seconds
|